Spring Batch Partition 병렬 처리 해결기

TL;DR
병렬처리는 아예 ItemReader에 AbstractPagingItemReader 재정의후 페이징 doPageRead() 재정의하면 쉽게 처리가능. ListItemReader에는 InputStreamReader가 없어서 non-thread-safe해서, 아예 병렬처리 없이 싱글 스레드로 돌았던 것.
해결을 위한 여정..
병렬 처리는 스프링 배치에서 여러가지 방법을 제공해주는데 그중 가장 좋은 방법인 partition방식을 이용해서 해결하려 했다.
문제는 병렬처리는 마음처럼 잘 해결이 안되는 게 문제였는데, 동기식으로 Blocking되는 방식으로 시스템이 돌아갔던것이 가장 큰 문제였다.
| 배치 개수 | 배치 방법 | 시작 시간 | 종료 시간 | 총 걸린시간 | 비고 |
|---|---|---|---|---|---|
| 700개 | partition | 2021년 12월 10일 오후 2:38 | 2021년 12월 10일 오후 2:38 | 15초 | 쓰레드풀 5개로 고정 |
| 동기적 | 2021년 12월 10일 오후 2:43 | 2021년 12월 10일 오후 2:43 | 11초 | ||
| partition | 2021년 12월 10일 오후 2:52 | 2021년 12월 10일 오후 2:53 | 13초 | 20개 / page 5개 단위 | |
| 7000개 | partition | 2021년 12월 10일 오후 3:05 | 2021년 12월 10일 오후 3:06 | 1분 53초 | 20개 |
| 동기적 | 2021년 12월 10일 오후 3:10 | 2021년 12월 10일 오후 3:11 | 1분 54초 | ||
| partition | 2021년 12월 10일 오후 3:30 | 2021년 12월 10일 오후 3:31 | 1분54초 | 20개 / page 20개 단위 이렇게 하니까 그냥 에러나는 Step 생김. Connection pool 부족이 원인인듯 |
막상 배치 방식을 파티션 단위로 분리했음에도 불구하고, 시간 자체는 동일하게 나오는 이슈가 발 생했었다.

로그를 보면 알겠지만, 파티션을 위한 쓰레드자체는 분리되어있지만, 이게 그렇다고 분리되어서 따로 병렬적으로 실행되는게 아닌, 원래 한 작업을 기다리고, 다음 작업이 실행되는 방식임.
그래서 시간이 쓰레드별로 누적해서 문제가 처리되었고, 결국 시간이 누적으로 걸려서 동기적으로 짠 코드랑 크게 다르지 않은 시간을 보여줬다.
시행착오들
문제는 이런 문제 해결을 위해서 필요한 점이 정확하게 무엇인지 파악하기가 어려웠는데, Blocking이 될만한 곳이 어디인지 파악하는 것이 급선무였다.
일단, API 콜의 문제인가 싶어, 아예 비동기적으로 구성해서 Mono라던가, Flux를 통해서 값을 처리하려 했으나, 애초에 값자체가 안들어가고 바로 Response를 Return 해버렸다.
대신 이런 시행 착오를 통해서 얻어낸 점이 하나 있었는데, 1. 비동기적 값이 안들어가게 하자 처리률이 확 늘어났었다. 값이 없는 경우 병렬처리가 되는 것 처럼 보였다. 왜냐하면, 시간의 누적이 없었기 때문이었다.
결국 파트장님에게 질문후 어느정도 윤곽을 찾아냈는데,
Can I use FlatfileItemReader with Taskexecutor?
Can I use FlatfileItemReader with Taskexecutor in spring batch?? I have implemented FlatFileItemReader with ThreadPoolTaskExecutor. When I print the records in ItemProcessor, I do not get consist...
stackoverflow.com
FlatfileItemReader의 경우 Not Thread-safe하기 때문에, Thread-Safe하게 코딩하기 위해서는 SynchronizedItemStreamReader 을 통해서, 렙핑해줘야했다.
Reader 자체를 래핑했어야했고 내 코드에서는
@Bean
public SynchronizedItemStreamReader<MovieCompany> itemReader() {
ListItemReader<MovieCompany> itemReader = ... // your item reader
SynchronizedItemStreamReader<MovieCompany> synchronizedItemStreamReader = new SynchronizedItemStreamReader<>();
synchronizedItemStreamReader.setDelegate(itemReader);
return synchronizedItemStreamReader;
}이런 식으로 처리하려 했으나, 실패했는데, Casting 오류가 발생했다. 왜 도대체 캐스팅 오류가 발생했는지에 대해서 찾아보니..
SynchronizedItemStreamReader 은 상속관계는 아래와 같은데,
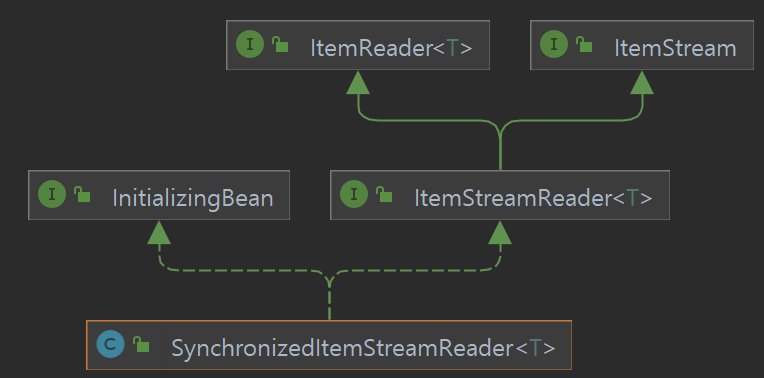
ItemStreamReader를 통해서 동기화와 관련한 여러 구현을 Interface로써 사용할 수 있도록 도와주고 있었다. 즉, ItemStream이나, ItemStreamReader만 구현하고 있다면 동기화 프로세스를 사용할 수 있었는데...
Casting 문제는 ListItemReader는 ItemStream을 implements하지 않고 있었던것이 문제이다.
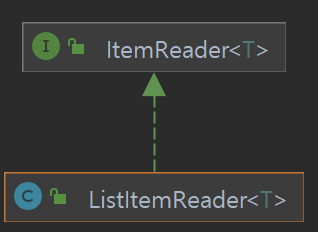
즉, 기본 ListItemReader를 동기적으로 구현하기 위해서는 ItemStreamReader를 구현하던... ItemStream을 통해서 동기적인 처리를 해버리는 방식을 통해서 내부 메소드를 재정의를 통해서 구현하면 동기적인 코드를 구현할 수 있었는데...
ItemStream의 구현해야할 코드들은 예상보다 좀 많이 까다로운 함수들이었다.
public interface ItemStream {
void open(ExecutionContext executionContext) throws ItemStreamException;
void update(ExecutionContext executionContext) throws ItemStreamException;
void close() throws ItemStreamException;
}→ open, update, close등 정체를 정확하게 파악하기도 어려웠으며, 내부적으로 Sync를 맞춰줘야하는 작업을 개발자 스스로 잡아줘야했었는데 솔직히 그정도로 자세히 하긴 어려워보였다.
대충 포기하고, mutil-Thread 방식으로 구현하려 했으나, (Step 자체를 paging할 수 있게 아예 나눠버리고 그걸 병렬처리하면 되는 방식으로 구현하려했다. 지금 생각해보면 안될 가능성이 커보였다. 결국 Reader때문에... 병렬처리 안될수도..?)
드디어 성공!
퇴근직전에 동욱님이 작성한 QueryDSL을 페이징 처리가능하게 구현했었던 Reader를 만들었던것을 보고, 이거면 혹시 가능할지도라고 생각했던 내 생각이 매우 좋은 발상이었는데,
Spring Batch와 Querydsl | 우아한형제들 기술블로그
{{item.name}} Spring Batch와 QuerydslItemReader 안녕하세요 우아한형제들 정산시스템팀 이동욱입니다. 올해는 무슨 글을 기술 블로그에 쓸까 고민하다가, 1월초까지 생각했던 것은 팀에 관련된 주제였습
techblog.woowahan.com
Spring Batch - Reference Documentation
If a group of Steps share similar configurations, then it may be helpful to define a "parent" Step from which the concrete Steps may inherit properties. Similar to class inheritance in Java, the "child" Step combines its elements and attributes with the pa
docs.spring.io
생각해보면 QueryDSL은 내부적으로 Spring Batch에서는 제공하는 Reader가 없어서 커스텀한 Reader를 만들었다는 것에 착안했고
예제로 사용한
public class ProductRepositoryItemReader extends AbstractPagingItemReader<Product> {을 참고해보니까 오히려 좀 더 구현하기에 쉬운 방식이 아닌가 싶어서 이방식을 통해서도, API Batch 방식을 좀 더 개선해볼 수 있겠다 싶었다.
AbstractPagingItemReader 를 알아볼 필요가 있는데, 이 친구를 잘 살펴보면 연관관계가 아래와 같은데,
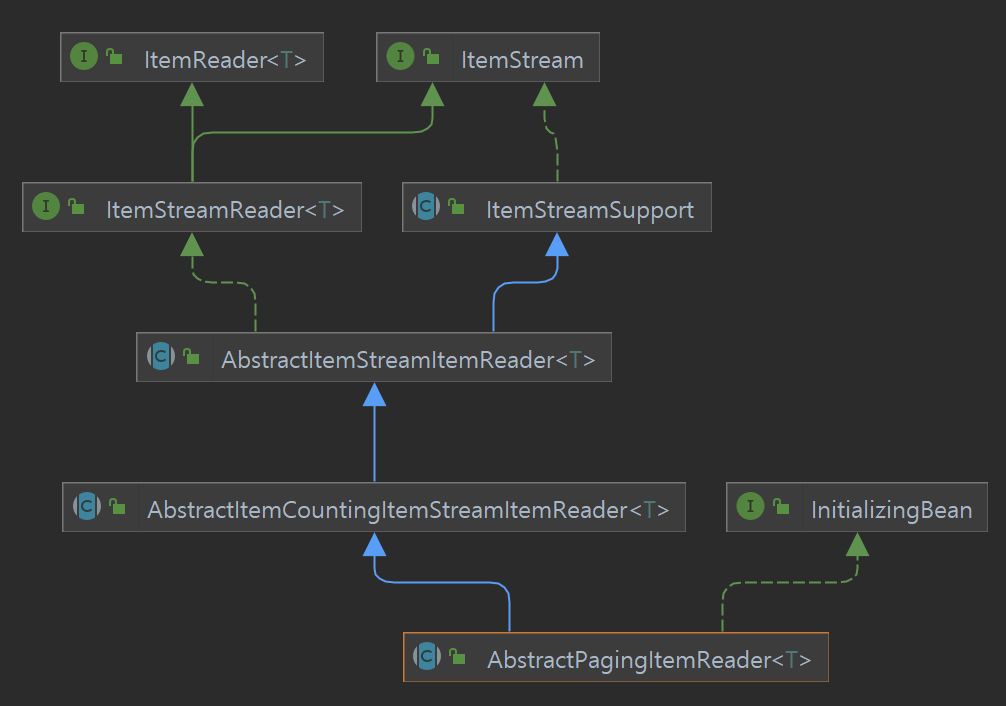
오잉? 아래아래쪽만 가도 ItemReader과 ItemStreamReader를 통해서 implemnet되어있기도 하고, 많이 쉽게, 구현할 수 있을지도 모른다 생각했다.
참고로, AbstractItemStreamItemReader, AbstractItemCountingItemStreamItemReader 보다 훨씬 쉽게 구현할 수 있으며, CountingItem의 경우 Open,closed, update와 같이 복잡하고 어려운 Deep Dive한 코드를 건들어야했다.
여기서 구현해야할 점은 두가지이다.
abstract protected void doReadPage(); //페이징해서 결과 만들어냄.
abstract protected void doJumpToPage(int itemIndex); //혹시 모를 중복을 건너 뛰는 페이징 함수.주석에서 알아봤듯 doReadPage()와 doJumpToPage()를 동시에 구현해야하는데, 실제로 jump의 경우 잘 사용하지 않았고,
doReadPage() 의 작동방식을 정확하게 파악하기가 상당히 까다로웠는데,
protected T doRead() throws Exception {
synchronized (lock) {
if (results == null || current >= pageSize) {
if (logger.isDebugEnabled()) {
logger.debug("Reading page " + getPage());
}
doReadPage(); //여기서 사용되었다.
page++;
if (current >= pageSize) {
current = 0;
}
}
int next = current++;
if (next < results.size()) {
return results.get(next);
}
else {
return null;
}
}
}여기서 사용하는 리더는 Reader는 proccessor에 넣을 값을 리턴해주는 것인(리턴타입이 T이므로) 듯했고, doReadPage()를 그럼 어케 구현할것인가에 대해 고민이 깊어졌다. 여기서 나는 이 정확한 로직 프로세스를 판단하기 어려웠고, 이전에 사용하던 public T read()를 그대로 오버라이딩 해서 사용하니, 병렬적으로 다시 작동하지 않았다.
즉, 무조건 doReadPage를 사용해야했었는데 종료 조건을 어떤식으로 구성해야할지 몰랐다..
그래서 일단 값을 계속 전달해주는 방식으로 구현했으나.. 그렇게 하다보니까 이 배치 작업이 종료되지 않았다.
내부적인 코드를 확인해보고 어떤 방식으로 돌아가는지에 대해서 열심히 찾아보고 열심히 문제 해결을 해본 결과, 다음과 같은 프로세스를 가지고 있었다.
파티션 프로세스를 알아보자...
결국 이 Partition을 하는 이유는 처음에는 청크를 짚고 넘어가야 한다. 기본적으로 이 파티션에서 값을 읽기 위해서는 청크단위의 Reader를 읽고 프로세싱하고, 청크단위로 넣게 된다. (청크단위로 넣지않으면 애초에 Paging 하는 의미도 없을것이다.)
그럼 이 파티션은 그것을 Reader를 더 세분화하게 잘게 쪼개서 그것을 병렬적으로 처리하고 싶은 것이므로, doReadPage(), doRead() 의 프로세스를 잘 이해해보면 좋다.
결국 doRead는 한 개의 아이템만 뱉는게 주 목적이다.
즉, result가 null이거나 current보다 pageSize가 크면 0 page를 늘리고 PageSize 비교해서 current=0 만들면 다시 pagesize개 만큼 가져오고..
를 doReadpage가 해야하는 역할인데, PageSize 갯수만큼을 매번 Result에 삽입하는 것이 이 메소드가 해야할 역할이다.
결국 가장 이해에 어려움을 겪었던 점은 도대체 doReadPage()로 이 전체 배치를 어떤 방식으로 종료 하는 가였다.
이게 결국 청크단위로 확인해봐야지 좀 더 감이 잡히는데,
ChunkOrientedTasklet 은 청크를 다루는 클래스이고, 여기서 ChunkProvider 가 Reader를 담당하여 관리를 하게 된다.
물론 ChunkProvider가 인터페이스로 구현되어있으므로, 실 클래스로 사용되어지는
chunkProvider.provide() 를 통해 청크 사이즈로 데이터를 가져오므로, Provide를 확인해야하며, SimpleChunkProvider를 확인해보자면, 다음과 같이
public Chunk<I> provide(final StepContribution contribution) throws Exception {
final Chunk<I> inputs = new Chunk<>();
repeatOperations.iterate(new RepeatCallback() {
@Override
public RepeatStatus doInIteration(final RepeatContext context) throws Exception {
...
try {
item = read(contribution, inputs); //일단 읽고 read함수는 SimpleChunckProvider의 함수..
}
if (item == null) { //item중에 null이면, 종료시켜버림
inputs.setEnd();
return RepeatStatus.FINISHED;
}
inputs.add(item); //청크에 계속 밀어넣고..
}
//아래 쪽으로 쭉 내려가면....
protected I read(StepContribution contribution, Chunk<I> chunk) throws SkipOverflowException, Exception {
return doRead(); //실제로 사용하는 것은 doRead() 이역시 현 class에 존재
}
protected final I doRead() throws Exception {
try {
listener.beforeRead();
I item = itemReader.read(); //결국 itemReader에서 read 함수를 통해 읽어서 오는 것.
if(item != null) {
listener.afterRead(item);
}
return item;
}
그러면 Read는 어디서 또 사용하나..? 우리는 지금 AbstractPagingItemReader 에서는 doRead밖에 없는데...?
AbstractItemCountingItemStreamItemReader 에서 Read가 있는데
@Nullable
@Override
public T read() throws Exception, UnexpectedInputException, ParseException {
if (currentItemCount >= maxItemCount) { //만약 maxItemCount만 정해놓으면 파티션별로 최대 갯수도 지정 가능하지만, 굳이 그럴필요가 있나 싶다.
return null;
}
currentItemCount++;
T item = doRead(); // 이 Read에서도 doRead만 잘 이용하면 되는 것이었음.
if(item instanceof ItemCountAware) {
((ItemCountAware) item).setItemCount(currentItemCount);
}
return item;
}결국 SimpleChunkProvider 에서 이 코드와 같이
if (item == null) { //item중에 null이면, 종료시켜버림
inputs.setEnd();
return RepeatStatus.FINISHED;
}결국 Null만 리턴해주면 되는 문제이기 때문에, doPageRead()를 통해서 null를 리턴해주던가... 아니면 아까처럼 maxItemCount를 통해서 null 리턴해주는 방식으로 구현하게된다면 알아서 Paging과 관련한 처리가 완료되어진다.
@Override //페이지 직접 읽기.
protected void doReadPage() {
if (results == null) {
results = new LinkedList<>();
} else {
results.clear();
}
int curr = this.start+getPage();
// log.info("현재 쓰레드의 [{}] 현재 curr 값: {}, END: {}",Thread.currentThread().getName(), curr, this.end);
if(curr<=this.end) {
ResponseEntity<kobisResponse> res = client.get().uri("/company....?itemPerPage=10&curPage="+curr)
.retrieve().toEntity(kobisResponse.class)
.block();
results.addAll(res.getBody().companyListResult.getCompanyList());
}
}아쉬운 점은 getPage()를 건들기가 상당히 애매하다는 것이다. abstract class에서 이미 모든 것을 다 구현 되어서 getPage와 관련한 값을 변경할 수는 없었고, 나는 시작 번호 + page를 늘려가는 방식으로 구현했다.
만약 page 까지 구현 가능했다면? 아마 int curr과 같이 각 파티션 마다 다른 페이지 번호를 적용하는것에 애를 먹지는 않았을 것 같다.
다음과 같이 코드 구현을 하게되면, 정말 다시 병렬처리가 된다.

각각의 쓰레드의 큰 영향을 주지 않기 때문에, 문제없이 파티셔닝 할 수 있다.
6. Spring Batch 가이드 - Chunk 지향 처리
Spring Batch의 큰 장점 중 하나로 Chunk 지향 처리를 얘기합니다. 이번 시간에는 Chunk 지향 처리가 무엇인지 한번 살펴보겠습니다. 6-1. Chunk? Spring Batch에서의 Chunk란 데이터 덩어리로 작업 할 때 각 커
jojoldu.tistory.com
👆참고: Batch 구현 레포지토리
혹시 몰라서 레포지토리를 파놓고, 직접 구현한 것을 만들어 뒀다. 차후에 좀 더 Readme쪽을 수정해서 이해하기 쉽도록 구현기를 작성하던, 배치 프로세스에 대해서 좀 더 자세하게 작성해볼 예정이다!
GitHub - ventulus95/SpringBatch
Contribute to ventulus95/SpringBatch development by creating an account on GitHub.
github.com
'Spring' 카테고리의 다른 글
| 스프링 롤백 테스트 하는 방식에 대한 생각 (1) | 2022.05.01 |
|---|---|
| Spring Batch를 활용한 토이프로젝트 - 1. 영화 업체를 가져와보자! (3) | 2022.03.13 |
| Spring boot 버전별 업데이트 사항 정리 - 1. 2.4버전 업데이트 (0) | 2021.12.05 |
| Spring Boot와 React를 분리해서 연동해보자 2) Spring Boot 구성 (1) | 2021.09.19 |
| Spring Boot와 React를 분리해서 연동해보자 1) React 구성 (3) | 2021.06.07 |